-
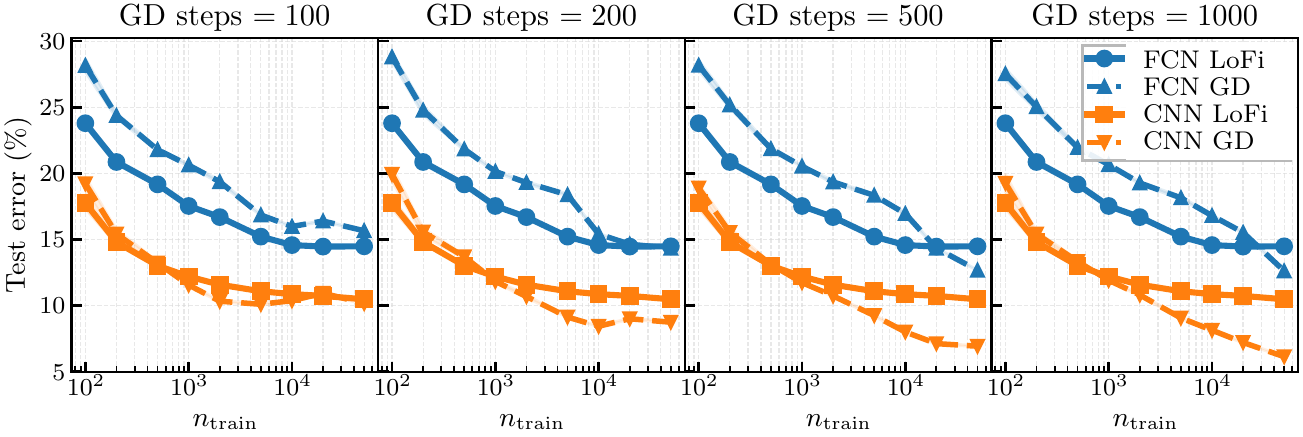 Neural LoFi versus gradient descent/backpropagation.
Neural LoFi versus gradient descent/backpropagation.
-
Scaling Laws from Sequential Feature Recovery: A Solvable Hierarchical Model
Arie Wortsman-Zurich, Hugo Tabanelli, Yatin Dandi, Florent Krzakala, Bruno Loureiro
HiLD Workshop, ICML 2026
-
Deep Learning of Compositional Targets with Hierarchical Spectral Methods
Hugo Tabanelli, Yatin Dandi, Luca Pesce, Florent Krzakala
International Conference on Machine Learning (ICML), 2026
-
Provable Learning of Random Hierarchy Models and Hierarchical Shallow-to-Deep Chaining
Yunwei Ren, Yatin Dandi, Florent Krzakala, Jason D. Lee
Conference on Learning Theory (COLT), 2026
-
The Computational Advantage of Depth: Learning High-Dimensional Hierarchical Functions with Gradient Descent
Yatin Dandi, Luca Pesce, Lenka Zdeborová, Florent Krzakala
Spotlight, NeurIPS 2025
-
Fundamental Limits of Learning in Sequence Multi-Index Models and Deep Attention Networks: High-Dimensional Asymptotics and Sharp Thresholds
Emanuele Troiani, Hugo Cui, Yatin Dandi, Florent Krzakala, Lenka Zdeborová
International Conference on Machine Learning (ICML), 2025
-
A Random Matrix Theory Perspective on the Spectrum of Learned Features and Asymptotic Generalization Capabilities
Yatin Dandi, Luca Pesce, Hugo Cui, Florent Krzakala, Yue M. Lu, Bruno Loureiro
Oral, AISTATS 2025
-
Fundamental Limits of Weak Learnability in High-Dimensional Multi-Index Models
Emanuele Troiani, Yatin Dandi, Leonardo Defilippis, Lenka Zdeborová, Bruno Loureiro, Florent Krzakala
AISTATS 2025
-
Asymptotics of Feature Learning in Two-Layer Networks after One Gradient-Step
Hugo Cui, Luca Pesce, Yatin Dandi, Florent Krzakala, Yue M. Lu, Lenka Zdeborová, Bruno Loureiro
Spotlight, ICML 2024
-
The Benefits of Reusing Batches for Gradient Descent in Two-Layer Networks: Breaking the Curse of Information and Leap Exponents
Yatin Dandi, Emanuele Troiani, Luca Arnaboldi, Luca Pesce, Lenka Zdeborová, Florent Krzakala
ICML 2024
-
Online Learning and Information Exponents: The Importance of Batch Size and Time/Complexity Tradeoffs
Luca Arnaboldi, Yatin Dandi, Florent Krzakala, Bruno Loureiro, Luca Pesce, Ludovic Stephan
ICML 2024
-
Repetita Iuvant: Data Repetition Allows SGD to Learn High-Dimensional Multi-Index Functions
Luca Arnaboldi, Yatin Dandi, Florent Krzakala, Luca Pesce, Ludovic Stephan
Preprint, arXiv, 2024
-
How Two-Layer Neural Networks Learn, One (Giant) Step at a Time
Yatin Dandi, Florent Krzakala, Bruno Loureiro, Luca Pesce, Ludovic Stephan
Journal of Machine Learning Research (JMLR); invited talk, NeurIPS 2023 M3L Workshop
-
Universality Laws for Gaussian Mixtures in Generalized Linear Models
Yatin Dandi*, Ludovic Stephan*, Florent Krzakala, Bruno Loureiro, Lenka Zdeborová
NeurIPS 2023
-
Understanding Layer-Wise Contributions in Deep Neural Networks through Spectral Analysis
Yatin Dandi, Arthur Jacot
Preprint, arXiv, 2021
